时间相关命令 时间分为三种格式
1.时间戳:从1970年到现在的秒数
time.time
2.格式化的字符串形式
time.strftime(‘%Y-%m-%d %H:%M%S %p’)
3.结构化的时间
res=time.localtime
print(res)
print(res.tm_year)
4.datetime
import datetime
print(datetime.datetime.now())
直接获取到格式化的时间格式
时间格式的转换 时间格式转换是其三种时间格式的相互转换,结构化时间(struct_time),时间戳(timestamp),格式化的字符串(format_string)
struct_time转换成时间戳 1 2 3 import time time .localtime ()print (time.mktime(s_time)
时间戳转换成struct_time 1 2 tp_time=time .time ()print (time.localtime(tp_time)
strcut_time转换成格式化的字符串 1 2 s_time=time.localtime()%Y -%m -%d %H :%M %S %p ',s_time)
真正需要掌握的是format string <—> timestamp
random模块 1 2 3 4 5 6 7 8 9 10 import random random .random ()) random .randint(1 ,3 ) random .randrange(1 ,3 ) 1 ,'aaa' ,[2 ,3 ]) 1 ,'23131d' ,[4 ,5 ]) 1 ,3 ) item =[1 ,2 ,3 ,4 ,5 ]random .shuffle(item )
os模块 os模块是与操作系统交互的一个接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 os .getcwd() 获取当前工作目录,即当前python脚本工作的目录路径os .chdir("dirname" ) 改变当前脚本工作目录;相当于shell下cdos .curdir 返回当前目录: ('.' )os .pardir 获取当前目录的父目录字符串名:('..' )os .makedirs('dirname1/dirname2' ) 可生成多层递归目录os .removedirs('dirname1' ) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推os .mkdir('dirname' ) 生成单级目录;相当于shell中mkdir dirnameos .rmdir('dirname' ) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirnameos .listdir('dirname' ) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印os .remove () 删除一个文件os .rename ("oldname" ,"newname" ) 重命名文件/目录os .stat('path/filename' ) 获取文件/目录信息os .sep 输出操作系统特定的路径分隔符,win下为"\\" ,Linux下为"/" os .linesep 输出当前平台使用的行终止符,win下为"\t\n" ,Linux下为"\n" os .pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:os .name 输出字符串指示当前使用平台。win->'nt' ; Linux->'posix' os .system("bash command" ) 运行shell命令,直接显示os .environ 获取系统环境变量os .path .abspath(path ) 返回path 规范化的绝对路径os .path .split(path ) 将path 分割成目录和文件名二元组返回os .path .dirname(path ) 返回path 的目录。其实就是os .path .split(path )的第一个元素os .path .basename(path ) 返回path 最后的文件名。如何path 以/或\结尾,那么就会返回空值。即os .path .split(path )的第二个元素os .path .exists(path ) 如果path 存在,返回True;如果path 不存在,返回Falseos .path .isabs(path ) 如果path 是绝对路径,返回Trueos .path .isfile(path ) 如果path 是一个存在的文件,返回True。否则返回Falseos .path .isdir(path ) 如果path 是一个存在的目录,则返回True。否则返回Falseos .path .join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略os .path .getatime(path ) 返回path 所指向的文件或者目录的最后存取时间os .path .getmtime(path ) 返回path 所指向的文件或者目录的最后修改时间os .path .getsize(path ) 返回path 的大小
1 2 3 4 5 6 7 8 9 10 11 12 在Linux和Mac平台上,该函数会原样返回path ,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为饭斜杠。os .path .normcase('c:/windows\\system32\\' ) 'c:\\windows\\system32\\' os .path .normpath('c://windows\\System32\\../Temp/' ) 'c:\\windows\\Temp' '/Users/jieli/test1/\\\a1/\\\\aa.py/../..' print (os .path .normpath(a))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 os 路径处理os os ,sysos .path .normpath(os .path .join(os .path .abspath(__file__),os .pardir, #上一级os .pardir,os .pardirpath .insert (0 ,possible_topdir)os .path .dirname(os .path .dirname(os .path .dirname(os .path .abspath(__file__))))
sys模块 1 2 import sysprint (sys.argv)
sys.argv用于获取向文件传递的参数
例如:
python3 run.py 1 2 3
其中的1, 2,3就分别是三个参数
sys.argv[0]为文件名, 123,分别就是后面对应的位置参数。
例如:
以argv来实现cp命令(cp 源文件 目标文件),实现复制粘贴文件的效果
1 2 3 4 5 6 7 8 9 10 11 12 13 import sys1 ]2 ]try :with open (r'%s' %cs_1,mode="rb" ) as file1:with open (r'%s' %cs_2,mode="wb+" ) as file2:except IOError:print ("没有该文件" )else :print ("内容写入文件成功" )
执行效果:(得在Windows命令行console执行)
(pyproject) E:\pyproject\py_study1>python study1.py upload_file.py 2.py
打印进度条: 1 2 3 4 5 6 7 import timeres = '' for i in range (50 ):res +='#' sleep (0.5 )print ('\r[%-50s]' % res ,end='' )50 ,-为左对齐,50 为其长度固定为50 ,由于只输出一行,让其为每次叠加一个#的进度条,所以其换行符为空,并且\r跳到其行首,使其覆盖
模拟打印下载进度条: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import time0 30000 while recv_size < total_size:0.1 )1024 percent = recv_size / total_sizeif percent > 1 :percent = 1 int (50 * percent ) * '#' print ('\r[%-50s] %d%%' ) % (res,int (100 *percent )),end='' )50 s]为其打印进度条,%d%%显示百分比,百分比为其下载进度分数x100.但recv_size一直累加可能会超出总大小本身,其比例也会超过100 %,这是可以用if 判断其大于1 时使其等于1.
shutil模块 引入: import shutil
copy()
copy2()
copyfileobj()
copyfile()
copytree()
copymode()
copystat()
rmtree()
move()
which()
disk_usage()
归档和解包操作
解包:将归档的文件进行释放。
压缩:压缩时将多个文件进行有损或者无损的合并到一个文件当中。
解压缩:就是压缩的反向操作,将压缩文件中的多个文件,释放出来。
注意:压缩属于归档!
unpack_archive()
get_archive_formats()
get_unpack_formats()
json&pickle模块 之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
1 2 3 4 1 import json2 x="[null,true,false,1]" 3 print (eval(x)) #报错,无法解析null类型,而json就可以4 print (json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,’状态’会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json 如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
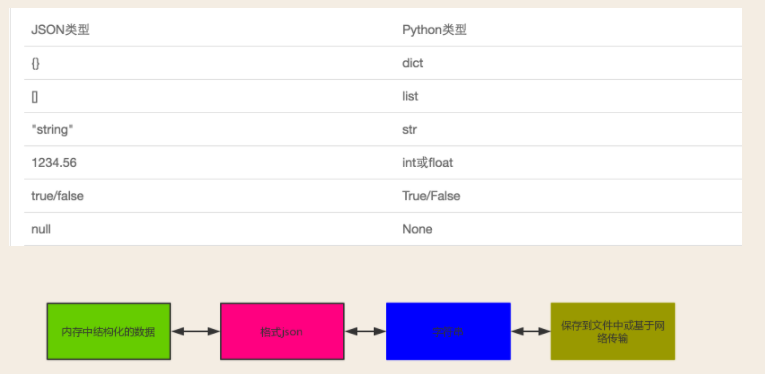
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
如何序列化与反序列化 1 2 3 4 5 import jsonres =json.dumps([1,'aaa' ,True ,False ])print (res.type(res))l =json.loads(res)print (l,type(l))
运行结果:
[1, “aaa”, true, false] <class ‘str’>
json.dumps是序列化转换,将列表转换为json格式,其格式变为了str。
json.loads是反序列化转换,将其又转回了原来的列表格式。
示例2:存储为json格式
1 2 3 4 import jsonres =json.dumps([1 ,'aaa' ,True,False])open ("1.json" ,mode ="wt" ,encoding='utf-8' ) as file :file .write (res )
运行结果:
再读取json格式将其反序列化转换成原格式:
1 2 3 4 5 import jsonwith open ("1.json" ,mode='rt' ) as file :a =file .read ()a )
运行结果:
[1, ‘aaa’, True, False]
简单方法实现:
1 2 3 4 import json"1.json" ,mode="wt" ,encoding='utf-8' ) as file :dump ([1 , 'aaa' , True , False ],file )
1 2 3 4 import jsonwith open ("1.json" ,mode='rt' ) as file :load (file )
dump和load可以省略其文件的write和read方法
pickle 1 2 3 import pickleres =pickle.dumps({1 ,2 ,3 ,4 ,5 })print (res,type(res))
将python序列化转换成pickle形式,反序列化为loads,与json一致。
configparser模块 配置文件如下:
1 2 3 4 5 6 7 8 9 10 11 12 user =egonage =18is_admin =true salary =31
读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import configparser.ConfigParser ().read ('a.cfg' ).sections () #['section1' , 'section2' ] print (res) .options ('section1' )print (options) ['k1' , 'k2' , 'user' , 'age' , 'is_admin' , 'salary' ] .items ('section1' )print (item_list) [('k1' , 'v1' ), ('k2' , 'v2' ), ('user' , 'egon' ), ('age' , '18' ), ('is_admin' , 'true' ), ('salary' , '31' )] .get ('section1' ,'user' )print (val) #egon .getint ('section1' ,'age' )print (val1) 18 .getboolean ('section1' ,'is_admin' )print (val2) #True .getfloat ('section1' ,'salary' )print (val3) 31.0
改写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import configparserconfig =configparser.ConfigParser()'a.cfg' ,encoding ='utf-8' )'section2' )'section1' ,'k1' )'section1' ,'k2' )print (config.has_section('section1' ))print (config.has_option('section1' ,'' ))'egon' )set ('egon' ,'name' ,'egon' )set ('egon' ,'age' ,18) #报错,必须是字符串'a.cfg' ,'w' ))
基于上述方法添加一个ini文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import configparserconfig = configparser.ConfigParser()config ["DEFAULT" ] = {'ServerAliveInterval' : '45' ,'Compression' : 'yes' ,'CompressionLevel' : '9' }config ['bitbucket.org' ] = {}config ['bitbucket.org' ]['User' ] = 'hg' config ['topsecret.server.com' ] = {}config ['topsecret.server.com' ]'Host Port' ] = '50022' # mutates the parser'ForwardX11' ] = 'no' # same hereconfig ['DEFAULT' ]['ForwardX11' ] = 'yes' open ('example.ini' , 'w' ) as configfile:config .write (configfile)
hashlib模块 1 2 3 4 5 # 1、什么叫hash :hash 是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的内容,经过运算得到一串hash 值 # 2、hash 值的特点是: # 2.1 只要传入的内容一样,得到的hash 值必然一样=====>要用明文传输密码文件完整性校验 # 2.2 不能由hash 值返解成内容=======》把密码做成hash 值,不应该在网络传输明文密码 # 2.3 只要使用的hash 算法不变,无论校验的内容有多大,得到的hash 值长度是固定的
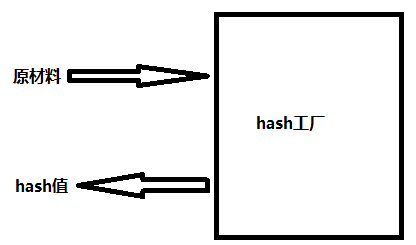
hash算法就像一座工厂,工厂接收你送来的原材料(可以用m.update()为工厂运送原材料),经过加工返回的产品就是hash值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 1 import hashlib2 3 m=hashlib.md5 ()# m=hashlib.sha256 ()4 5 m.update('hello'.encode('utf8 '))6 print(m.hexdigest()) #5 d41402 abc4 b2 a76 b9719 d911017 c592 7 8 m.update('alvin'.encode('utf8 '))9 10 print(m.hexdigest()) #92 a7 e713 c30 abbb0319 fa07 da2 a5 c4 af11 12 m2 =hashlib.md5 ()13 m2 .update('helloalvin'.encode('utf8 '))14 print(m2 .hexdigest()) #92 a7 e713 c30 abbb0319 fa07 da2 a5 c4 af15 16 '''17 注意:把一段很长的数据update多次,与一次update这段长数据,得到的结果一样18 但是update多次为校验大文件提供了可能。19 '''
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
1 2 3 4 5 6 7 1 import hashlib2 3 # ######## 256 ########4 5 hash = hashlib.sha256(6 hash.update(7 print (hash.hexdigest())#e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 进行进一步的处理然后再加密:
1 2 3 4 5 import hmac.new ('hello' .encode ('utf-8' ),digestmod='md5' )h1 .update ('world' .encode ('utf-8' ))print (h1.hexdigest()
suprocess模块 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 1 import subprocess2 3 ''' 4 sh-3.2# ls /Users/egon/Desktop |grep txt$ 5 mysql.txt 6 tt.txt 7 事物.txt 8 ''' 9 10 res1=subprocess.Popen('ls /Users/jieli/Desktop' ,shell=True ,stdout=subprocess.PIPE)11 res=subprocess.Popen('grep txt$' ,shell=True ,stdin=res1.stdout,12 stdout=subprocess.PIPE)13 14 print (res.stdout.read().decode('utf-8' ))15 16 17 18 res1=subprocess.Popen('ls /Users/jieli/Desktop |grep txt$' ,shell=True ,stdout=subprocess.PIPE)19 print (res1.stdout.read().decode('utf-8' ))20 21 22 23 24 25 import subprocess26 res1=subprocess.Popen(r'dir C:\Users\Administrator\PycharmProjects\test\函数备课' ,shell=True ,stdout=subprocess.PIPE)27 res=subprocess.Popen('findstr test*' ,shell=True ,stdin=res1.stdout,28 stdout=subprocess.PIPE)29 30 print (res.stdout.read().decode('gbk' ))
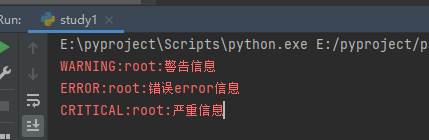
logging模块 1.日志级别以及模块 1 2 3 4 5 6 import logging debug ("调试" )info ("消息信息" )warning ("警告信息" )error ("错误error信息" )"严重信息" )
logging为模块名,有5种输出级别,对应调试,信息,警告,错误,严重错误。
该段代码运行效果:
logging.告警级别 本质上就是直接在对应位置输出对应信息,信息内容包含在括号里面,这里打印时默认只输出了warning及其以上的信息,说明默认输出日志级别为warning。
logging.basicConfig #======介绍
format参数中可能用到的格式化串:
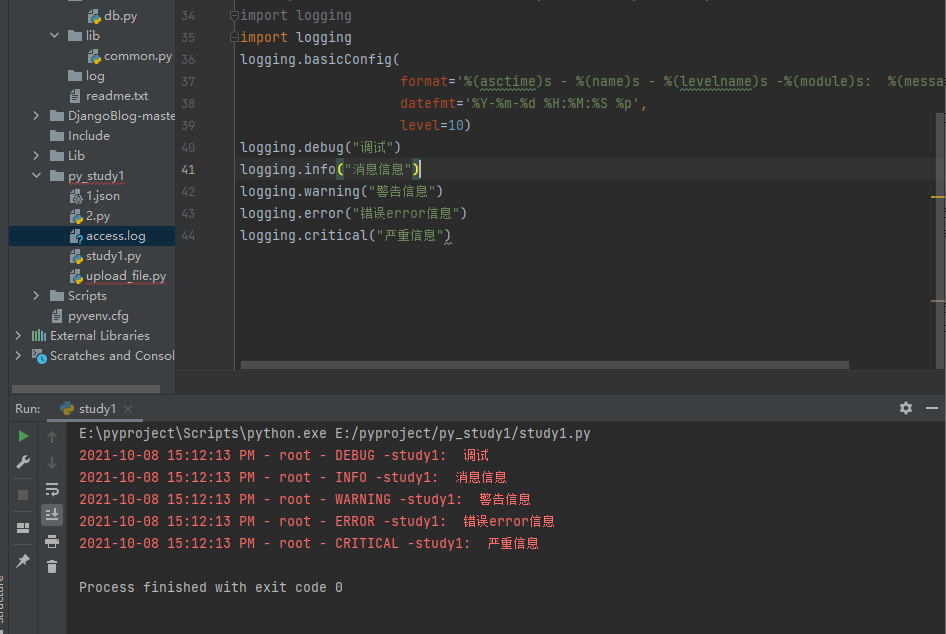
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 logging filename ='access.log' ,format ='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s' ,datefmt ='%Y-%m-%d %H:%M:%S %p' ,level =10)debug ('调试debug' )info ('消息info' )warning ('警告warn' )error ('错误error' )'严重critical' )
filename指定了日志文件,format指定其日志输出格式,datefmt指定日志输出时间的格式,level指定其日志输出级别,默认为30
level为10,20,30,40,50,对应调试,信息,警告,错误和严重错误。
日志输出结果:
如果这里不指定filename则默认输出到pycharm屏幕(python屏幕)
日志字典 其作用为让日志在读取格式时直接通过自身模块从字典里读取形成多种格式的方法,字典本身多个key固定的名称。
settings.py: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 standard_format = '%(asctime)s - %(threadName)s:%(thread)d - 日志名字:%(name)s - %(filename)s:%(lineno)d -' \'%(levelname)s - %(message)s' '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' '%(asctime)s] %(message)s' 3 、日志配置字典'version' : 1 , #版本,可以随意定义'disable_existing_loggers' : False , # 禁用已经存在的logger实例,固定格式'formatters' : {'standard' : {'format' : standard_format'simple' : {'format' : simple_format'test' : {'format' : test_format'filters' : {},# 过滤'handlers' : {'console' : {'level' : 'DEBUG' ,'class' : 'logging.StreamHandler' , # 打印到屏幕'formatter' : 'simple' 'default' : {'level' : 'DEBUG' ,'class' : 'logging.handlers.RotatingFileHandler' , # 保存到文件'maxBytes' : 1024 *1024 *5 , # 日志大小 5 M'maxBytes' : 1000 ,'backupCount' : 5 ,'filename' : 'a1.log' , # os.path.join(os.path.dirname(os.path.dirname(__file__)),'log' ,'a2.log' )'encoding' : 'utf-8' ,'formatter' : 'standard' ,'other' : {'level' : 'DEBUG' ,'class' : 'logging.FileHandler' , # 保存到文件'filename' : 'a2.log' , # os.path.join(os.path.dirname(os.path.dirname(__file__)),'log' ,'a2.log' )'encoding' : 'utf-8' ,'formatter' : 'test' ,'loggers' : {'kkk' : {'handlers' : ['console' ,'other' ], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕'level' : 'DEBUG' , # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)'propagate' : False , # 默认为True ,向上(更高level的logger)传递,通常设置为False 即可,否则会一份日志向上层层传递'终端提示' : {'handlers' : ['console' ,], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕'level' : 'DEBUG' , # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)'propagate' : False , # 默认为True ,向上(更高level的logger)传递,通常设置为False 即可,否则会一份日志向上层层传递'' : {'handlers' : ['default' , ], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕'level' : 'DEBUG' , # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)'propagate' : False , # 默认为True ,向上(更高level的logger)传递,通常设置为False 即可,否则会一份日志向上层层传递
src.py(主文件): 1 2 3 4 5 6 7 8 import logging #导入logging模块import settings #导入settings文件,上面定义的settings.pyfrom logging import config,getLogger #导入config和getlogger 这里需要单独导入'终端提示' ) #loggers为发送者,这里也是将日志输出者定义为对应的loggers,并将其定义成一个变量。'logger4产生的info日志' )#调用info发送日志。
代码步骤: settings.py: standard_format,simple_format,test_format定义三种输出格式
LOGGING_DIC :
字典定义了日志输出相关配置
1.version,disable_existing_loggers 其格式固定就行
2.formatters 其中key也是固定的,里面定义了三种日志输出格式,这里里面的key和value都是自己定义的,其三种value也对应一开始定义的三种变量。
3.filters 略(过滤)
4.handlers:
1 handlers是日志的接收者,不同的handler 会将日志输出到不同的位置
这里定义了两种输出位置。level为输出级别,class为输出方式,formatter为其对应输出格式,filename输出文件,encoding输出字符。这里相当于定义其日志输出位置以及将上面定义的日志输出格式赋给日志这个日志输出位置。
5.loggers:
1 # loggers是日志的产生者,产生的日志会传递给handler然后控制输出
这里loggers与handlers相当于是下级对上级,loggers产生日志,handlers接受日志,两边都可以设置其level,如果loggers的level低于handlers,那么实际日志输出只会根据handlers的level来进行输出(因为loggers发送了低于handlers的日志,但handlers只会接受并输出自己的level以上的。),正常情况两边level应一致。
handlers定义其输出位置(方式),level为其输出级别,propagate固定false。
如果定义的loggers为空 ‘’ 的话,后面在使用getlogger找不到loggers的所有日志名都会匹配到空。
src.py 如上备注所示。
其本身格式基本上为固定,直接拿着两个文件稍作修改就可以用于各种工作场景,无需过分理解,能看懂代码格式即可
日志字典本身就算是python日志的功能之一,所以其字典里面需要定义固定的key让其logging模块去解析它。而非自己定义一个字典再自己去解析,其格式固定。
字典顺序:
loggers(日志输出者)-》handlers(接受者)-》formatters(日志输出格式(standard_format,simple_format,test_format)
日志轮转: 相当于日志备份,logging自带日志备份,可以设置日志最大大小和备份日志最大个数
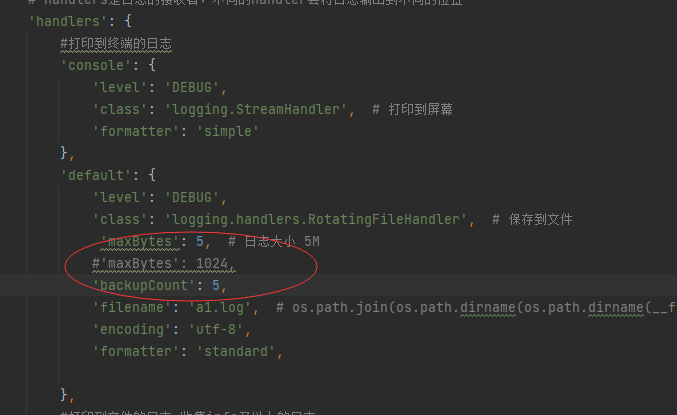
在字典handlers中有两个设置:maxbytes和backupcount
maxbytes为最大大小,其格式为字节
backupcount是最大备份文件为多少
1 2 3 4 5 6 import settings #导入settings文件,上面定义的settings.pyfrom logging import config,getLogger #导入config和getlogger 这里需要单独导入'随便输入' ) #loggers为发送者,这里也是将日志输出者定义为对应的loggers,并将其定义成一个变量。'logger4产生的info日志' )#调用info发送日志。
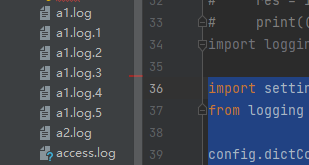
运行主代码程序输出日志以后,当日志大小大于5字节,就会备份成”文件名.1”,然后如果再执行程序,则会将1备份成2,将源文件备份成1,依次类推到5。