面向过程
核心是过程二字,过程是流水线,用来分步骤解决问题的
过程的核心思想是将程序流程化。
面向对象
核心是对象二字。
对象是“容器”,用来盛放东西。
类也是“容器”,该容器用来存放同类对象共有的数据与功能。
对象的核心思想是将程序容器化。将程序整合
类:
类似对象相似数据与功能的集合体
所以类体最常见的是变量与函数的定义,但是类体其实是可以包含任意其他代码
类体代码是在类定义阶段就会立即执行,会产生类的名称空间
调用类的过程又称为实例化。发生了三件事
1.先产生一个空对象
2.调用类中的__init__方法(对象初始化属性),然后将空对象(self)以及调用类时括号内传入的参数一同传入init方法,相当于定义对象时类传递的属性为对象属性
例:
duixiang=lei(‘1s’,2,3)
init方法
1、会在调用类时自动触发执行,用来为对象初始化自己独有的数据
2、__init__内应该存放是为对象初始化属性的功能,但是是可以存放任意其他代码,想要在
类调用时就立刻执行的代码都可以放到该方法内
3、__init__方法必须返回None ,
python中所有数据类型都为类(class),而将数据类型传入参数(数值)定义为变量本质上就是在定义对象,所有python一切皆为对象。
对象代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| class school:
school_name='OLDBOY'
def __init__(self,a,b):
self.address=a
self.nickname=b
self.classes=[]
def rekated_class(self,classobj):
self.classes.append(classobj)
def tell_class(self):
print(self.nickname,end=',')
for class_obj in self.classes:
class_obj.tell_course()
class_obj.tell_student()
class Class:
def __init__(self,name):
self.name=name
def related_course(self,coursename,student):
self.course=coursename
self.student=student
def tell_course(self):
print(self.name,end=',')
self.course.tell_info()
def tell_student(self):
self.student.tell_info()
class student:
def __init__(self,name,age,):
self.name=name
self.age=age
def tell_info(self):
print(f'学生:{self.name},年龄{self.age}')
class course:
def __init__(self,name,period,price):
self.name=name
self.period=period
self.price=price
def tell_info(self):
print(self.name,self.period,self.price)
student1=student('张三',15)
student2=student('李四',20)
course1=course('linux课程','6mons',2000)
course2=course('python课程','6mons',3000)
Class1 =Class('1班')
Class2 =Class('2班')
Class1.related_course(course1,student1)
Class2.related_course(course2,student2)
school1 = school('北京','北京校区')
school2 = school('上海','上海校区')
school1.rekated_class(Class1)
school2.rekated_class(Class2)
school1.tell_class()
school2.tell_class()
|
自定义私有属性
在定义类属性时,若在该属性前加上__,则该属性被定义为私有属性,即该属性不可被外部直接引用,只能在类的内部使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| class A(object):
def __init__(self):
self.__a = 1
def func(self):
print self.__a
a = A()
a.func()
#输出
1
a.__a
#输出
AttributeError: 'A' object has no attribute '__a'
|
然而Python对__a这个属性做了什么呢?实际上该属性并不是不存在的,当在某个属性前加上两个下划线后,python自动将其所在的类名追加在属性前导致其拥有了新的属性名,也由此实现了该属性不可引用的假象
1
2
3
4
5
6
7
8
9
10
11
12
13
| class A(object):
def __init__(self):
self.__a = 1
def func(self):
print self.__a
a = A()
a._A__a
#输出
1
|
property:
property是一个装饰器,用来绑定给对象的方法伪造成一个数据属性。
相当于对象中定义的函数正常情况下是 对象名.函数名(“参数”)来进行调用,如果是property装饰情况下调用方式将变为:
对象名.函数名,本质上调用方式和对象属性变为一至。
例:
1
2
3
4
5
6
7
8
9
10
11
12
| class someone(object):
def __init__(self,name,weight,height):
self.name = name
self.weight = weight
self.height = height
@property
def bmi(self):
return self.weight / (self.height ** 2)
obj1 = someone('张三',70,1.80)
print(obj1.bmi)
|
例2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class someone(object):
def __init__(self,name):
self.__name = name
@property
def name(self):
return self.__name
@name.setter
def name(self,val):
if type(val) is not str:
print('请传入str类型')
return
self.__name = val
@name.deleter
def name(self):
print('无法删除')
object1 = someone("张三")
print(object1.name)
object1.name = "李四"
print(object1.name)
del object1.name
|
结果:
张三
李四
无法删除
继承
继承是一种创建新类的方式,新建的类可以成为子类或者派生类,父类又可称为基类或超类
python支持多继承,在python中新建的类可以继承一个或多个父类
python2中有经典类和新式类:
新式类是指继承了object类的子类,经典类是指没有继承object类的子类。
1
2
3
4
5
6
7
8
9
10
11
| class cs1(object):
x=111
class cs2(object):
pass
class cs3(cs1):
pass
class cs4(cs2,cs1):
pass
print(cs3.x)
|
结果:
111
这里cs1和cs2为顶级类,下面的类定义时如果继承了cs1,则可拥有cs1的方法和属性,通过继承。
继承作用:解决类与类之间代码冗余问题
优点:子类可以同时遗传多个父类的属性,最大限度重用代码
缺点:
1.违背人的思维习惯:继承表达的是一种什么“是”什么的关系
2.代码可读性会变差
3.扩展性变差,不建议使用多继承
4.如果无法避免使用多继承,应该使用Mixins
例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| class OldboyPeople:
school = 'OLDBOY'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
class Student(OldboyPeople):
def choose_course(self):
print('学生%s 正在选课' % self.name)
class Teacher(OldboyPeople):
def __init__(self, name, age, sex, salary, level):
OldboyPeople.__init__(self,name,age, sex)
self.salary = salary
self.level = level
def score(self):
print('老师 %s 正在给学生打分' % self.name)
tea_obj=Teacher('egon',18,'male',3000,10)
tea_obj.score()
|
teacher这里在继承父类__init__属性name,age,sex的时候需要通过OldboyPeople.init(self,name,age, sex)来调用到自己的init方法里面。
如果子类中没有方法或属性而父类拥有,这个时候会调用父类的方法属性。而如果子类的父类都有情况下,会优先使用子类的。如果这时子类拥有与父类同名的方法属性且仍需要调用父类方法属性时需要在子类的单独定义出来,例如这里的init方法。
菱形问题
大多数面向对象语言都不支持多继承,而在Python中,一个子类是可以同时继承多个父类的,这固然可以带来一个子类可以对多个不同父类加以重用的好处,但也有可能引发著名的 Diamond problem菱形问题(或称钻石问题,有时候也被称为“死亡钻石”),菱形其实就是对下面这种继承结构的形象比喻
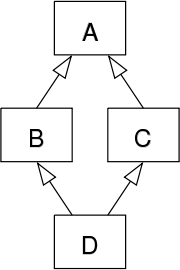
1
| A类在顶部,B类和C类分别位于其下方,D类在底部将两者连接在一起形成菱形。
|
这种继承结构下导致的问题称之为菱形问题:如果A中有一个方法,B和/或C都重写了该方法,而D没有重写它,那么D继承的是哪个版本的方法:B的还是C的?如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B,C):
pass
obj = D()
obj.test()
|
要想搞明白obj.test()是如何找到方法test的,需要了解python的继承实现原理
继承原理
python到底是如何实现继承的呢? 对于你定义的每一个类,Python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表,如下
1
2
| >>> D.mro()
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
|
python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。 而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1
2
3
| 1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
|
所以obj.test()的查找顺序是,先从对象obj本身的属性里找方法test,没有找到,则参照属性查找的发起者(即obj)所处类D的MRO列表来依次检索,首先在类D中未找到,然后再B中找到方法test
ps:
1
2
| 1.由对象发起的属性查找,会从对象自身的属性里检索,没有则会按照对象的类.mro()规定的顺序依次找下去,
2.由类发起的属性查找,会按照当前类.mro()规定的顺序依次找下去,
|
深度优先和广度优先
参照下述代码,多继承结构为非菱形结构,此时,会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性
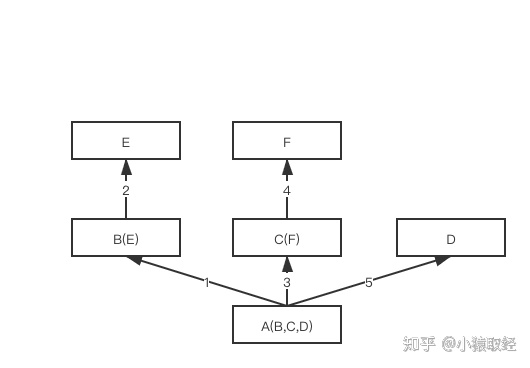
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| class E:
def test(self):
print('from E')
class F:
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D:
def test(self):
print('from D')
class A(B, C, D):
pass
print(A.mro())
'''
[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>, <class 'object'>]
'''
obj = A()
obj.test()
|
如果继承关系为菱形结构,那么经典类与新式类会有不同MRO,分别对应属性的两种查找方式:深度优先和广度优先
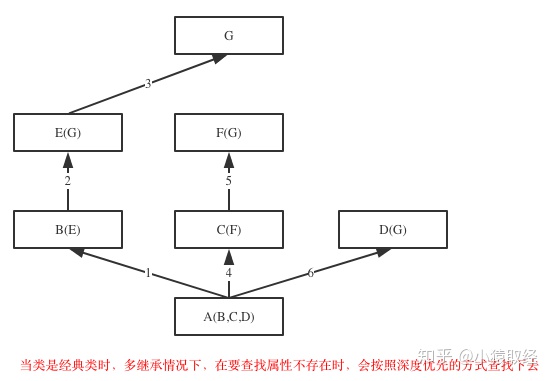
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class G:
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
pass
obj = A()
obj.test()
|
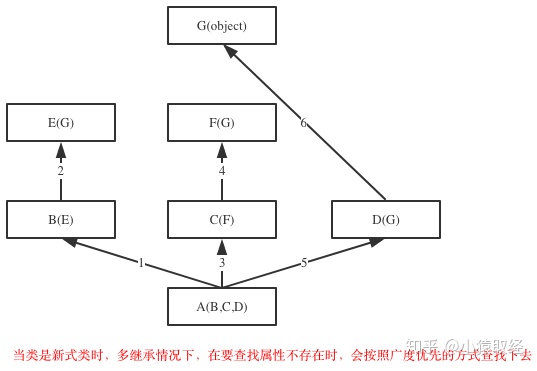
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class G(object):
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
pass
obj = A()
obj.test()
|
mixins
mixins是多继承的正确打开方式,其核心要素为:
在多继承背景下尽可能的提升多继承代码可读性