IO模型简介 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 """ 我们这里研究的IO模型都是针对网络IO的 Stevens在文章中一共比较了五种IO Model: * blocking IO 阻塞IO * nonblocking IO 非阻塞IO * IO multiplexing IO多路复用 * signal driven IO 信号驱动IO * asynchronous IO 异步IO 由signal driven IO(信号驱动IO)在实际中并不常用,所以主要介绍其余四种IO Model。 """
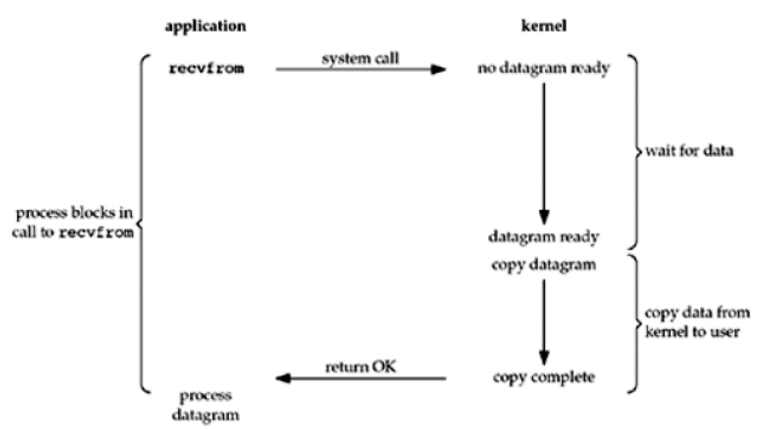
阻塞IO模型 最广泛的模型是阻塞I/O模型,默认情况下,所有套接口都是阻塞的。 进程调用recvfrom系统调用,整个过程是阻塞的,直到数据复制到进程缓冲区时才返回(当然,系统调用被中断也会返回)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 """ 我们之前写的都是阻塞IO模型 协程除外 """ import socket'127.0.0.1' ,8080 ))5 )while True :while True :try :1024 )if len (data) == 0 :break print (data)except ConnectionResetError as e:break
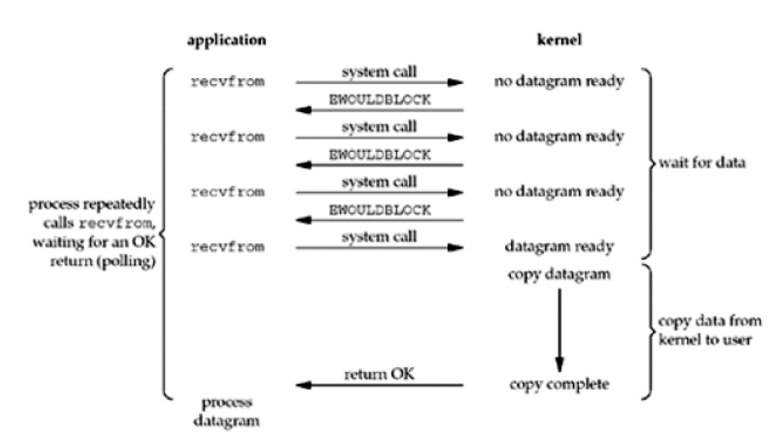
非阻塞IO 当我们把一个套接口设置为非阻塞时,就是在告诉内核,当请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误。当数据没有准备好时,内核立即返回EWOULDBLOCK错误,第四次调用系统调用时,数据已经存在,这时将数据复制到进程缓冲区中。这其中有一个操作时轮询(polling)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 """ 要自己实现一个非阻塞IO模型 """ import socketimport time'127.0.0.1' , 8081 ))5 )False )while True :try :except BlockingIOError:for conn in r_list:try :1024 ) if len (data) == 0 : continue except BlockingIOError:continue except ConnectionResetError:for conn in del_list:import socket'127.0.0.1' ,8081 ))while True :b'hello world' )1024 )print (data)
总结
1 2 3 4 5 6 7 8 """ 虽然非阻塞IO给你的感觉非常的牛逼 但是该模型会 长时间占用着CPU并且不干活 让CPU不停的空转 我们实际应用中也不会考虑使用非阻塞IO模型 任何的技术点都有它存在的意义 实际应用或者是思想借鉴 """
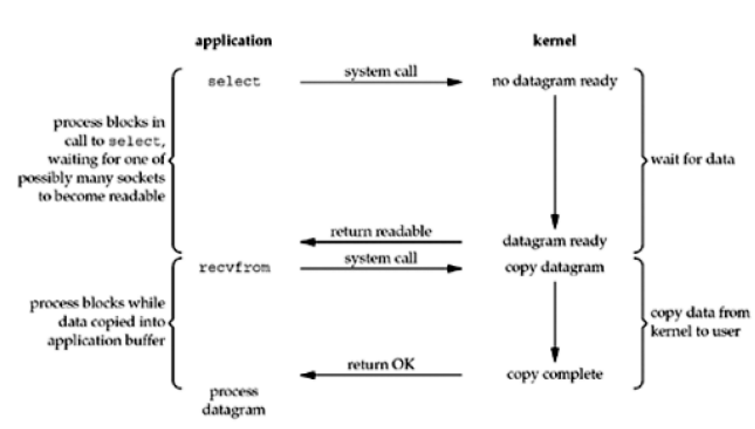
IO多路复用 此模型用到select和poll函数,这两个函数也会使进程阻塞,select先阻塞,有活动套接字才返回,但是和阻塞I/O不同的是,这两个函数可以同时阻塞多个I/O操作 ,而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写(就是监听多个socket )。select被调用后,进程会被阻塞,内核监视所有select负责的socket,当有任何一个socket的数据准备好了,select就会返回套接字可读,我们就可以调用recvfrom处理数据。正因为阻塞I/O只能阻塞一个I/O操作,而I/O复用模型能够阻塞多个I/O操作,所以才叫做多路复用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 """ 当监管的对象只有一个的时候 其实IO多路复用连阻塞IO都比比不上!!! 但是IO多路复用可以一次性监管很多个对象 server = socket.socket() conn,addr = server.accept() 监管机制是操作系统本身就有的 如果你想要用该监管机制(select) 需要你导入对应的select模块 """ import socketimport select'127.0.0.1' ,8080 ))5 )False )while True :""" 帮你监管 一旦有人来了 立刻给你返回对应的监管对象 """ for i in r_list: """针对不同的对象做不同的处理""" if i is server:else :1024 )if len (res) == 0 :continue print (res)b'heiheiheiheihei' )import socket'127.0.0.1' ,8080 ))while True :b'hello world' )1024 )print (data)
总结
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 """ 监管机制其实有很多 select机制 windows linux都有 poll机制 只在linux有 poll和select都可以监管多个对象 但是poll监管的数量更多 上述select和poll机制其实都不是很完美 当监管的对象特别多的时候 可能会出现 极其大的延时响应 epoll机制 只在linux有 它给每一个监管对象都绑定一个回调机制 一旦有响应 回调机制立刻发起提醒 针对不同的操作系统还需要考虑不同检测机制 书写代码太多繁琐 有一个人能够根据你跑的平台的不同自动帮你选择对应的监管机制 selectors模块 """
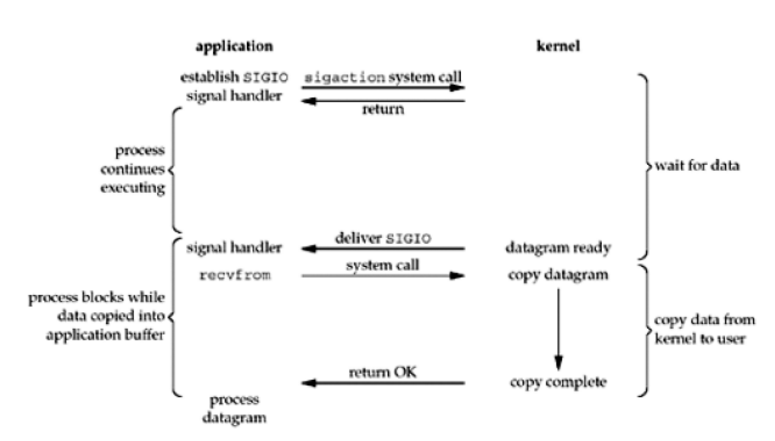
信号驱动I/O模型 首先我们允许套接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。当数据报准备好读取时,内核就为该进程产生一个SIGIO信号。我们随后既可以在信号处理函数中调用recvfrom读取数据报,并通知主循环数据已准备好待处理,也可以立即通知主循环,让它来读取数据报。无论如何处理SIGIO信号,这种模型的优势在于等待数据报到达(第一阶段)期间,进程可以继续执行,不被阻塞。免去了select的阻塞与轮询,当有活跃套接字时,由注册的handler处理。
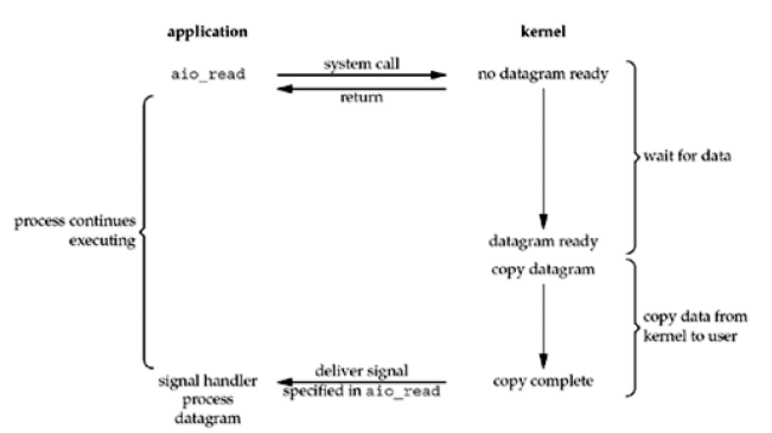
异步IO 进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
这个模型工作机制是:告诉内核启动某个操作,并让内核在整个操作(包括第二阶段,即将数据从内核拷贝到进程缓冲区中)完成后通知我们。
这种模型和前一种模型区别在于:信号驱动I/O是由内核通知我们何时可以启动一个I/O操作,而异步I/O模型是由内核通知我们I/O操作何时完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 """ 异步IO模型是所有模型中效率最高的 也是使用最广泛的 相关的模块和框架 模块:asyncio模块 异步框架:sanic tronado twisted 速度快!!! """ import threadingimport asyncio@asyncio.coroutine def hello ():print ('hello world %s' %threading.current_thread())yield from asyncio.sleep(1 ) print ('hello world %s' % threading.current_thread())
高性能IO模型浅析
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种:
(1)同步阻塞IO(Blocking IO):即传统的IO模型。
(2)同步非阻塞IO(Non-blocking IO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。注意这里所说的NIO并非Java 的NIO(New IO)库。
(3)IO多路复用(IO Multiplexing):即经典的Reactor设计模式,Java中的Selector和Linux 中的epoll都是这种模型。
(4)异步IO(Asynchronous IO):即经典的Proactor设计模式,也称为异步非阻塞IO。